
RTB(RealTime Bidding)实时竞价,是一种利用第三方技术在数以百万计的网站上针对每一个用户展示行为进行评估以及出价的竞价技术。与大量购买投放频次不同,实时竞价规避了无效的受众到达,针对有意义的用户进行购买。它的核心是DSP平台(需求方平台),RTB对于媒体来说,可以带来更多的广告销量、实现销售过程自动化及减低各项费用的支出。而对于广告商和代理公司来说,最直接的好处就是提高了效果与投资回报率。
由于实验室承接了DSP的算法优化项目,在此简单地对RTB及其涉及到的常用算法做一个介绍。
RTB架构
实时竞价(RTB)不同于传统广告的投放方式,传统的竞价搜索广告和上下文广告需要广告主事先为某关键字的广告设置一个竞标价格,而 RTB 是对每次有广告曝光机会的请求提交竞标价格,它要求时间非常短,常常小于 100ms。RTB 是专注于受众定向,而不是上下文定向。它基于用户数据来进行广告位购买,广告投放给特定的人群。
RTB系统的组成
RTB 广告生态系统主要包括四个平台:需求方平台(DSP),供应方平台(SSP),数据管理平台(DMP),广告交易平台(AD Exchange)。国内的RTB生态系统如下所示。
SSP 是 Supply Side Platform 的缩写,直译为供应方平台。它的主要服务对象是媒体,为其控制广告投放、广告位优化、收益管理以及展示广告有效性优化等。一般一个媒体会采用多个 SSP。SSP 需要处理的内容包括管理流量分配、调整广告底价、控制时段分配、筛选广告主、监控广告素材和分析流量数据。SSP 可以从不同的广告交易平台中筛选出出价可能更高的请求,其主要目的是帮助媒体优化营收。
DSP是需求方平台。在预算受限制的情况下,DSP 需要帮助每个广告主最大化其在广告投放周期内的广告点击次数。这通常需要 DSP 根据每个曝光的点击率来合理优化出价算法,使得广告活动的经费尽可能花费到那些能够获得点击的曝光机会上。DSP平台需要的功能算法有点击率预测算法、竞价算法和预算管理算法。
DMP是数据管理平台。它将多渠道来源的数据进行整合分析和规范化处理,并对数据做标签化管理,提高广告投放精准性,提升广告投放效果。DMP 可分为三种类型,第一种是由大型广告主自建的内部 DMP,数据只由广告公司自己使用,第二种是DSP 自建的 DMP,数据主要支持 DSP 自己投放广告,第三种就是独立的 DMP 公司,它的数据提供给广告主或 DSP 做数据支持,同时会收取相应报酬。DMP 的功能有数据收集、数据分类、数据分析、数据迁移和对接、可扩展。
广告交易平台(Ad Exchanges)是一种汇聚了各种媒体流量的大规模交易平台,是 DSP 实现精准受众购买的交易场所。它联系 DSP 买方与 SSP 卖方,按照每个广告曝光进行实时竞价购买。
除了上述的几个重要平台之外,还有采购交易平台(Trading desk)、程序化创意平台(programmatic creative)、广告验证(ad verification)等。采购交易平台(Trading desk)是程序化独立媒体交易平台,功能类似于 DSP,通过对接多个 DSP来进行广告的优化投放,它能够将各类购买方式统一管理和预算分配,对品牌广告的有效管理甄别垃圾媒体。程序化创意平台(programmatic creative)是动态实时创意优化平台,他帮助广告主评估和优化广告创意,能更好的在提升在实时竞价广告投放中的效果。广告验证(ad verification)是安全有效的购买广告的手段,被许多广告代理视作广告策略中必不可少的一个组成部分。
RTB工作流程
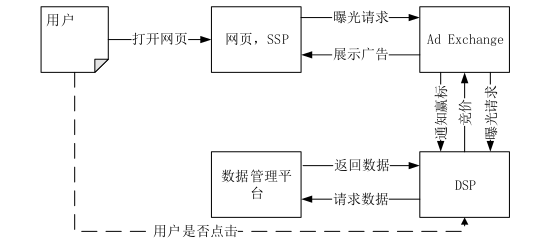
媒体的广告位有许多是通过合约广告的方式出售给一些品牌广告商,也有许多剩余广告位留给 RTB 实时竞价。接下来用一个例子来说明 RTB 是如何工作的。假设媒体web 页面右上角有一个 250*200 的广告位想通过 RTB 方式出售。
1) 用户使用浏览器访问这个 web 页面,此时产生出了一个曝光展示。
2) 媒体将广告位展示信息通过 SSP 传递给 Ad Exchanges。
3) Ad Exchanges 对多家与之对接的 DSP 发送竞价请求。
4) DSP 通过 DMP 数据管理平台或自身的用户数据库来推断用户属性,通过DSP的竞价引擎判断是否参与竞价,若参与则给出竞标价格。
5) DSP 将竞价响应传递给 Ad Exchanges。
6) Ad Exchanges 接收到所有 DSP 的响应或到达截止时间(通常规定是100ms),确定获胜的 DSP。
7) Ad Exchanges 通知 SSP 竞拍的赢家,SSP 发送广告曝光请求给广告服务器。
8) 广告服务器将广告投送到用户浏览的 web 页面。
整个过程对于用户体验来说几乎是瞬间完成的,当打开网页即可看到对应的广告。
点击率预测算法
CTR架构
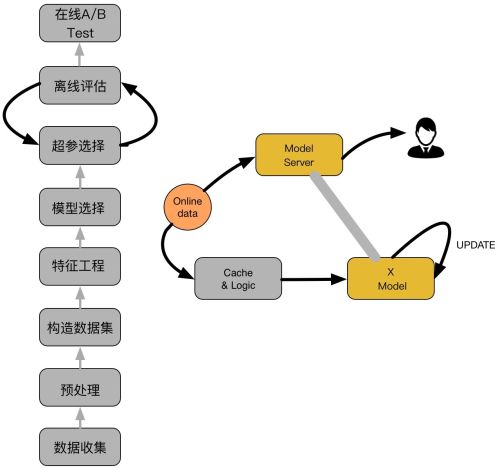
主要包括两大部分:离线部分、在线部分,其中离线部分目标主要是训练出可用模型,而在线部分则考虑模型上线后,性能可能随时间而出现下降,若出现这种情况,可选择使用Online-Learning来在线更新模型:
离线部分
- 数据收集:主要收集和业务相关的数据,通常会有专门的同事在app位置进行埋点,拿到业务数据;
- 预处理:对埋点拿到的业务数据进行去脏去重;
- 构造数据集:经过预处理的业务数据,构造数据集,在切分训练、测试、验证集时应该合理根据业务逻辑来进行切分;
- 特征工程:对原始数据进行基本的特征处理,包括去除相关性大的特征,离散变量one-hot,连续特征离散化等等;
- 模型选择:选择合理的机器学习模型来完成相应工作,原则是先从简入深,先找到baseline,然后逐步优化;
- 超参选择:利用gridsearch、randomsearch或者hyperopt来进行超参选择,选择在离线数据集中性能最好的超参组合;
- 在线A/B Test:选择优化过后的模型和原先模型(如baseline)进行A/B Test,若性能有提升则替换原先模型;
在线部分
- Cache & Logic:设定简单过滤规则,过滤异常数据;
- 模型更新:当Cache & Logic 收集到合适大小数据时,对模型进行pretrain+finetuning,若在测试集上比原始模型性能高,则更新model server的模型参数;
- Model Server:接受数据请求,返回预测结果;
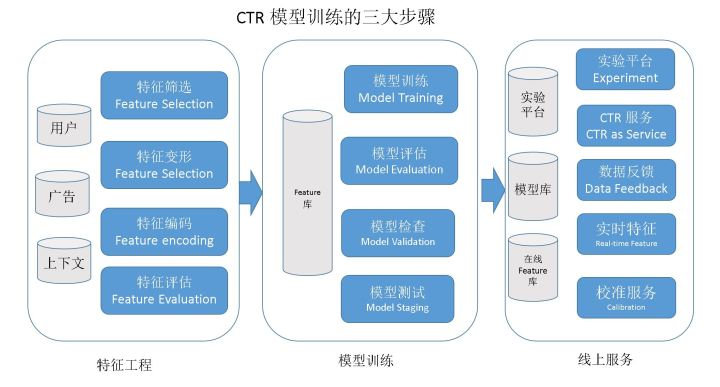
特征工程
- 二值化: 将一个特征转化为用0/1表示的多个特征。解决两个特征的差没有意义的情况,就是独热编码。
- 交叉:两个特征组合成一个特征,一般为广告CTR和某个特征的组合。特征经过交叉之后可以将二值化阶段拆分的特征重新合并为一个。特征需要根据人和广告间的关系来变化,如广告和性别的交叉,即特征值为广告在男性用户上的点击率。
- 平滑:对反馈CTR特征进行平滑处理,避免因数据稀疏性对整体点击反馈CTR的影响。
利用贝叶斯,假设一,所有的广告有一个自身的CTR,这些CTR服从一个Beta(α,β)分布。二,对于某一广告,给定展示次数时和它自身的ctr,它的点击次数服从一个伯努利分布 Binomial(I, CTR)。如果用r表示点击率,I表示展示,C表示点击。这两个假设可以用下面的数学表示。根据这两个假设,假如已经有了很多个广告投放数据,I1,C1,I2,C2……In,Cn,就可以根据这些投放数据列出似然函数求解这个极大似然问题,得到两个参数alpha(α)和beta(β),然后每个广告的点击率就可以利用这两个参数计算后验CTR(平滑CTR)了,公式为:r=(C + alpha) / (I + alpha + beta) - 离散化:将连续特征进行离散化,将一个连续特征拆分为几个离散特征。
特征在不同区间的重要程度是不一样的,连续特征默认特征的重要程度和特征值之间是线性的关系,但往往是非线性的,即特征值在不同区间的重要程度是不一样的。等频离散化方式,离散化表示可以加速模型训练速度。 - 向量化:提高推荐的多样性
用户的特征无法拿到具体值,比如品牌特征,用户往往并不是只对某一品牌感兴趣,而是对多个品牌感兴趣,只是感兴趣的程度不一样,因此需要用向量来表示用户特征。
模型选择
1. LR:逻辑回归模型(Logistic Regression)

将CTR模型建模为一个分类问题,利用LR预测用户点击的概率。逻辑回归其实仅为在线性回归的基础上,套用了一个逻辑函数。若每次广告请求的信息提取为一个特征向量x,那么点击率可看做x的函数表示为: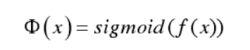
特征的线性和为: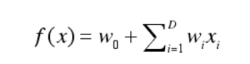
用sigmoid函数将范围限定到[0,1],利用y和x的概率密度结合点击率函数在一组数据量为m的数据样本求出其log似然函数为: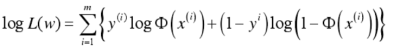
根据随机梯度下降迭代到收敛,则n维特征向量的第j 权重值为: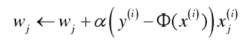
2. PLOY2
LR优点是简单高效,缺点也很明显,它太简单,视特征空间内特征之间彼此独立,没有任何交叉或者组合关系,这与实际不符合,比如在预测是否会点击某件t恤是否会点击,如果在夏天可能大部分地区的用户都会点击,但是综合季节比如在秋天,北方城市可能完全不需要,所以这是从数据特征维度不同特征之间才能体现出来的。因此,必须复杂到能够建模非线性关系才能够比较准确地建模复杂的内在关系,而PLOY2就是通过特征的二项式组合来建模这类特征的复杂的内在关系,二项式部分如下图公式: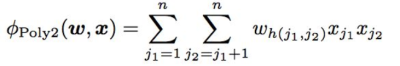
PLOY2有一个明显的问题,就是在实际场景中,大部分特征都是稀疏的,即大部分特征值为0,对这些稀疏的特征做二项式组合,会发现最后大部分特征值都是0,而在梯度更新时,当大部分feature为0时,其实梯度并不更新,所以PLOY2的方法在实际场景中并不能比较好地解决这类特征组合来建模更复杂线性关系的问题。
3. GBDT+LR
随着特征的增加,特征组合这件事将变得尤为困难,人力很难应付且会导致特征爆炸。特征爆炸带来两个问题,一是不太可能再用人力的方式去做特征组合的事,另一个问题是维度灾难。所以提出一种解决特征组合问题的方案,基本思路是利用树模型的组合特性来自动做特征组合,具体一点是使用了 GBDT 的特征组合能力。整体架构如下:
先在样本集上训练一个 GBDT 的树模型,然后使用这个树模型对特征进行编码,将原始特征 x 对应的叶子节点按照 01 编码,作为新的特征,叠加到 LR 模型里再训练一个 LR 模型。预测的时候也是类似的流程,先对原始特征 x 通过 GBDT 计算一遍,得到叶子节点情况,以图中为例,如果 x 落到第一棵树的第二个节点,第二棵树的第一个节点,则转换后的输入特征为 (0、1、0、1、0);
GBDT+LR 模型确实明显优于单独的 LR 模型, AUC 都有非常明显的提升,接近 10 个百分点。优点是可以逼近几乎任何函数的任何精度,缺点就是很容易过拟合,需要根据业务场景注意在树的棵数和深度上做一定的裁剪,才能平衡精度和过拟合。
4. Factorization Machine
FM 是一种可以自有设置特征组合度数的回归算法,通常 d=2 的 FM 拟合公式如下: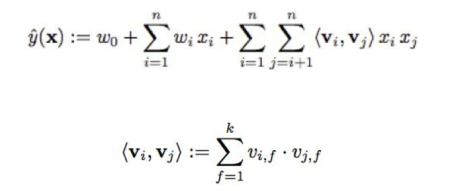
FM通过对二项式稀疏进行低维连续空间的转换,能够有效地解决PLOY2中存在的二次项系数在大规模系数数据下不更新的问题,不足之处是在 dense 数据集情况下,反而可能表现不佳。
5.深度学习DNN
深度学习采用神经网络技术也在不断影响点击率技术的发展。特别是DNN的开发平台,更多的广告和用户数据,更大的计算资源(包括GPU),这都给深度学习解决点击率预估的问题,奠定了好的基础。
6. 集成学习(Ensemble Learning)
集成学习通过训练多个分类器,然后把这些分类器组合起来使用,以达到更好效果。集成学习算法主要有Boosting和Bagging两种类型。
Boosting:通过迭代地训练一系列的分类器,每个分类器采用的样本的选择方式都和上一轮的学习结果有关。比如在一个年龄的预测器,第一个分类器的结果和真正答案间的距离(残差),这个残差的预测可以训练一个新的预测器进行预测。XGBoost是非常出色的Boosting工具,支持DT的快速实现。
Bagging:每个分类器的样本按这样的方式产生,每个分类器都随机从原样本中做有放回的采样,然后分别在这些采样后的样本上训练分类器,然后再把这些分类器组合起来。简单的多数投票一般就可以。这个类别有个非常著名的算法叫Random Forest,它的每个基分类器都是一棵决策树,最后用组合投票的方法获得最后的结果。
衡量点击预测率的准确性
AUC是常常被用于衡量点击率预估的准确性的方法。Precision/Recall;对于一个分类器,我们通常将结果分为:TP,TN,FP,FN。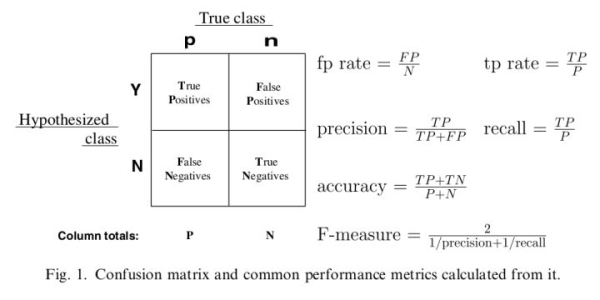
本来用Precision=TP/(TP+FP),Recall=TP/P,可以用于评估点击率算法的好坏,但是这种方法对于测试数据样本的依赖性非常大,稍微不同的测试数据集合,结果差异非常大。所以考虑使用一系列的点来描述准确性。做法如下:
1. 找到一系列的测试数据,点击率预估分别会对每个测试数据给出点击/不点击,和Confidence Score。
2. 按照给出的Score进行排序,那么考虑如果将Score作为一个Thresholds的话,考虑这个时候所有数据的 TP Rate 和 FP Rate; 当Thresholds分数非常高时,例如0.9,TP数很小,NP数很大,因此TP率不会太高;
3. 当选用不同Threshold时候,画出来的ROC曲线,以及下方AUC面积
4. 计算这个曲线下面的面积就是所谓的AUC值;AUC值越大,预测约准确。
竞价算法
竞价算法分为线性竞价和非线性竞价。其中,线性竞价算法包括固定竞价、随机竞价、真实价值竞价和分组竞价。另外还有基于赢标率的非线性竞价算法,又被称为综合竞价。
竞价算法概述
竞价算法的主要目标是,在预算限制下,选择符合广告活动目标特征的发布方平台以及用户群体,从而实现投资回报率以及关键指标 KPI的最大化。可将竞价问题建模为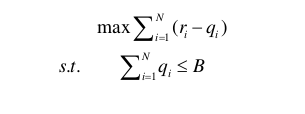
B为总预算,q为单次竞标成功后的实际花费,r为单次展示广告后的收益。r由展示广告后的用户点击率与转换率与转换收益相乘得出。点击率为用户点击广告次数与广告展示次数的比值,转换率为用户的转换行为次数与点击次数的比值,转换收益为单次转换为广告主带来的价值。而在实际问题中,转换行为十分稀疏,故r常常被简化为用户的点击率。通常来说,在每一次竞价中,竞价算法应该考虑到的影响出价的因素有预测出的用户点击率和与出价对应的赢标概率。
竞价机制
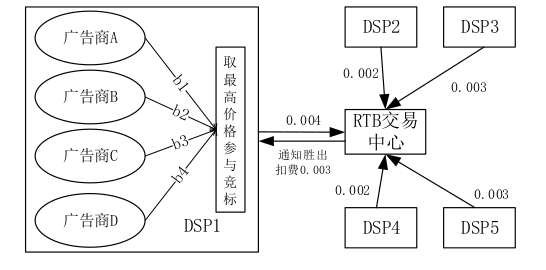
RTB 系统通常采用广义第二高价机制来进行收费,即竞价活动中出价最高的广告活动作为的获胜方,但获胜方实际只需要按照竞标价格中的第二高价付费。在实际应用中,SSP通常会设立地板价(Floor Price)和软地板价。
SSP为保证每个曝光机会的收益,只有最高的竞标价格超过地板价 的时候,交易才会成交,否则流标。
SSP 不仅为每个曝光机会设置地板价,而且还设置一个软地板价(软地板价高于地板价),最高竞标价格高于软地板价格时,才会按照第二高价成交,否则将按照第一高价成交。
线性竞价算法
固定竞价
固定竞价出价策略是指对于所有展示机会出一样的价格,这个模型唯一的参数就是其价格。由于获胜方的最终支付的费用是次高价,它所对应曝光日志中的成交价格大部分是远低于最初设定的固定价格。同时,在之后的实验结果比较当中我们也可以看到固定出价的好处仅仅是增加了曝光的可能性,但由于它没有预测每次曝光的点击率和转化率,因此在快速的用完预算之后,就提前结束后续的竞价机会,收益并不理想。
随机竞价
随机价格出价策略是指在一个给定价格区间里随机出价,唯一参数就是竞价的区间上限,而下限一般是 0。
真实价值竞价
真实价值出价策略,这是一种较为常用的出价策略,在这种出价策略中,一次曝光机会的出价取决于展示收益的预测和转换率预测。
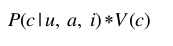
其中V(c)是关于广告 c 的价值,也就是收益, P(c | u , a , i)表示该次曝光的转换率, u 表示用户, a 表示广告商, i 表示特定的广告位。实际上,V(c)难以预测,通常假设V(c)为定值。则竞价价格正比于转换率。而在实际操作中,由于转换行为过于稀疏,难以估计,因此通常使用点击率代替转换率。 在这个策略中不存在参数。竞价价格正比于点击率。
分组竞价
分组出价,即按用户属性进行分组,每个组设定好一个基价,然后通过其它广告特征统计出的 CTR 分布决定参数因子,最后的出价是底价乘以因子后得到的价格。基价由账户管理员设定,账户管理员按历史投放数据预估每个用户分组的转化概率,概率高的一般基价也相应增高。预测点击率为当前竞标广告位的预测点击率,平均点击率由历史数据得出。引入参数Ф,Ф为预测点击率与平均点击率的比值:
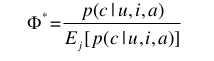
基于该参数提出两种竞价策略,一是简单将基准竞价与参数Ф相乘:

第二种策略就是将表示参数 Ф转化为影响价格的因子。简单来说就是对于任何比例值小于 0.8 的曝光都将影响因子设置为 0,也就是不参与竞价,在 0.8到 1 之间的曝光来说影响因子设置为 1,即保持原价,而大于 1.2 的曝光就将其影响因子设置为 2,也就竞价价格是标准价的两倍: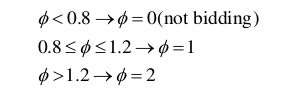
非线性竞价算法(综合竞价)
之前我们将竞价问题建模为预算限制下的点击率最大化问题:
使用数学公式描述出价方案如下: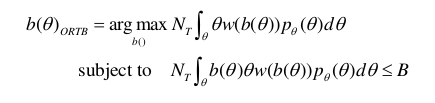
θ为预测点击率,p(θ)为点击率的概率密度函数,w(b(θ))是胜率函数。N是广告竞价的个数,B是固定预算。这样,竞价函数就成了具有约束条件的最优化问题,使用拉格朗日乘数法求解极值,化简得: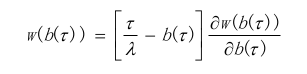
由于竞价函数和胜率函数中包含了点击率分布特性,p(θ)在过程中被消去。竞价函数与胜率函数间存在特定关系。
接下来的目标是根据历史数据通过统计学方法得到赢标率函数win(b)。
赢标率函数的得出:
DSP 方能够观测到的历史数据只有该 DSP 的出价和赢标后的实际出价。当DSP 最高价大于软地板价时,采用的第二高价竞价机制,因此,对于竞价成功的广告活动, DSP 方能观测到该次竞价的真实赢标价格,即第二高价。对于竞价活动中失败的记录,就只能得到自己投标失败的价格,该价格是这次竞标活动中赢标价格的下界,因为赢标价格不可能比竞标失败的价格更低,因此这种情况下无法观察第二高价。下面简述一个最基本的赢标率统计方案。
以计算得到赢标的广告活动实际支付价格的期望值,也就是平均
值,使用μ表示。以及 DSP 所有实际支付价格的方差,σ2表示,引入参数γ和sigmoid函数,公式如下,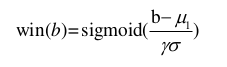
将赢标率函数带入上面简化后的关系式中,即可得出竞价函数。
竞价算法比较
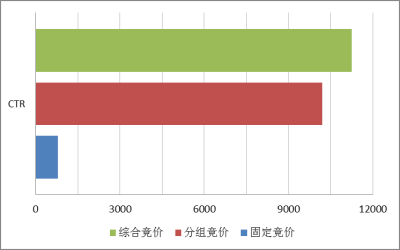
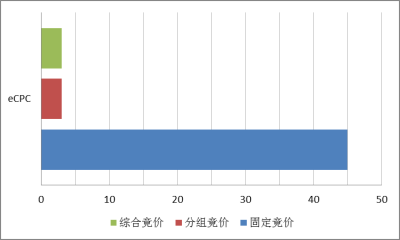
通过实验比较综合固定竞价、分组竞价和综合竞价(非线性竞价)的性能,性能指标为CTR(点击率)和eCPC(单次点击的成本)。
从 CTR 图来看,综合竞价要明显优于固定竞价,并略优于分组竞价,固定竞价的 CTR 很低的原因是由它没有预测每条曝光的点击率,测试数据中曝光日志的总成交价远远大于固定预算,所以固定竞价的策略早早的用完了预算,所以 CTR 非常低。从图中可以看出分组竞价和综合竞价的CTR 是固定竞价的十多倍。另外从eCPC方面分析,分组竞价和综合竞价每次点击的花费比固定竞价要明显低。
预算管理
实时竞价广告中,为广告商进行预算管理也是 DSP 的重点关注的问题。所谓预算管理是指,将广告商提供的时间周期总预算分配到各个时间段。其主要目标是在广告活动的预算限制下,使广告活动在整个预算周期内相对平稳的消耗预算,保证能在更长时间内有曝光效果,拥有持续性的广告推广效果。预算管理主要依赖于时间周期内关键指标的变化趋势,如流量,点击率等。
简单的预算管理方案有:1)设置KPI阈值,即在预测点击率大于阈值时才进行投标。2)根据时间段平均分配预算,但这种算法忽略了不同时间段流量大小和流量质量的不同。
因此,我们应该根据不同时间段的流量大小、流量质量(即点击率高低)和赢标率来分配预算。假设一天的总预算为 B,首先将一天划分为 T 个时间段,根据历史数据得到各个时间段赢标率平均值w(t) 和点击率的平均值θ(t),流量大小req(t)。则初始流量分配为:
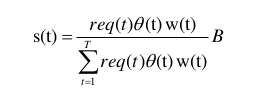
由于实时竞价过程是实时动态的,在实际运行的时候,各时段可能并没有使用完该时间分配到的所有预算。这就导致需要对后面每个时间段的预算进行更新。更新思路是每个时间段完结后的剩余预算,按照后面的流量,点击率和赢标率乘积比例再进行一次重新估计
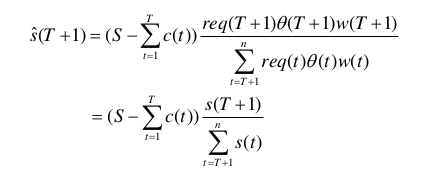
参考文献
[1] https://baike.baidu.com/item/RTB/3953125,RTB
[2] https://zhuanlan.zhihu.com/p/29053940,常见广告预估算法总结
[3] http://www.infoq.com/cn/articles/click-through-rate-prediction,从逻辑回归到深度学习,点击率预测技术面面观
[4] 崔云翔. 实时竞价网络广告博弈分析[D]. 对外经济贸易大学,2015
[5] 郭威. 针对在线广告实时竞价系统的相关算法研究[D].电子科技大学,2016.
[6] 乔宁. 多元逻辑回归在实时竞价中的应用研究[D].河北工业大学,2015.
[7] 张楠. 基于演化博弈的RTB网络广告产业链价值分配研究[D].南京财经大学,2016.
[8]朱丽辉. 在线广告中实时竞价机制研究与算法实现[D].华东师范大学,2015.
[9]李佩伦. 实时竞价系统中出价算法的研究与实现[D].电子科技大学,2017.
[10]韩静. 在线广告DSP平台实时竞价算法的研究与实现[D].上海交通大学,2015.